PQE Group staff comprises experienced and skilled experts in multidisciplinary teams, available to support your company achieving the highest levels of safety for your systems. Visit our Digital Governance services page to know more or to contact us, and find the most suitable solution for your company.
Connect with us
Executive Consultant & Partner @DOTS
Questions to be asked
The primary questions that must be answered before tackling this path, which is not purely technological, are:
- Is my ERP consistent with my company's mission? Inconsistencies could be due to technological limitations but also to changes in business or organizational models. A transformation initiative cannot be tackled by considering only the technological aspect without reviewing the processes.
- Is the data I get from the system reliable and unquestioned? An indicator is how much data present in ‘official systems’ is used to make important decisions, and how much it must be integrated with other tools (reprocessing, personal evaluations, Excel, etc.). Excessive use of personal IT tools (e.g., Excel) is often a sign of unreliability/incompleteness of company data.
- Can I measure the problems related to an incorrect flow of information? Often in an incorrectly mapped system, risks occur by performing the same activities several times causing problems both in terms of time spent and data quality. The need for independent paper-based controls or the use of paper as a data source instead of the system is an indication of poor reliability of the information creation process.
- Do I have the right perception of the obsolescence of the system? Obsolescence is also the use of expensive customizations that have now become standard. Checking the transactions used (especially if customized) is just a small and sometimes insufficient step; it is necessary to verify the efficiency of the process and, above all, to understand if the new features allow for a back to standard.
- Is there confidence that the system covers all recently introduced regulatory requirements? New regulatory or updated versions regarding the Pharma industry (for example, FDA CFR 21 in the US or EU GMP Vol 4 (for Europe), but also other rules, for example for privacy actions (such as EU GDPR) or national rules for taxes and accounting.
The big misunderstanding: IT optimization is a matter of systems
Generally, when there are problems in the IT environment, the first approach is to change the system, beginning with where the main problems have been found.
But this approach, of course pushed by the system’s seller, is highly ineffective; the system is only a part of the problem. Often the primary issues are related to the organization (this is also shown by the system integrator, but only during the project) and a lack of clear knowledge of real information flows (often flows found in SOPs are quite different from reality, typically in less structured enterprises).
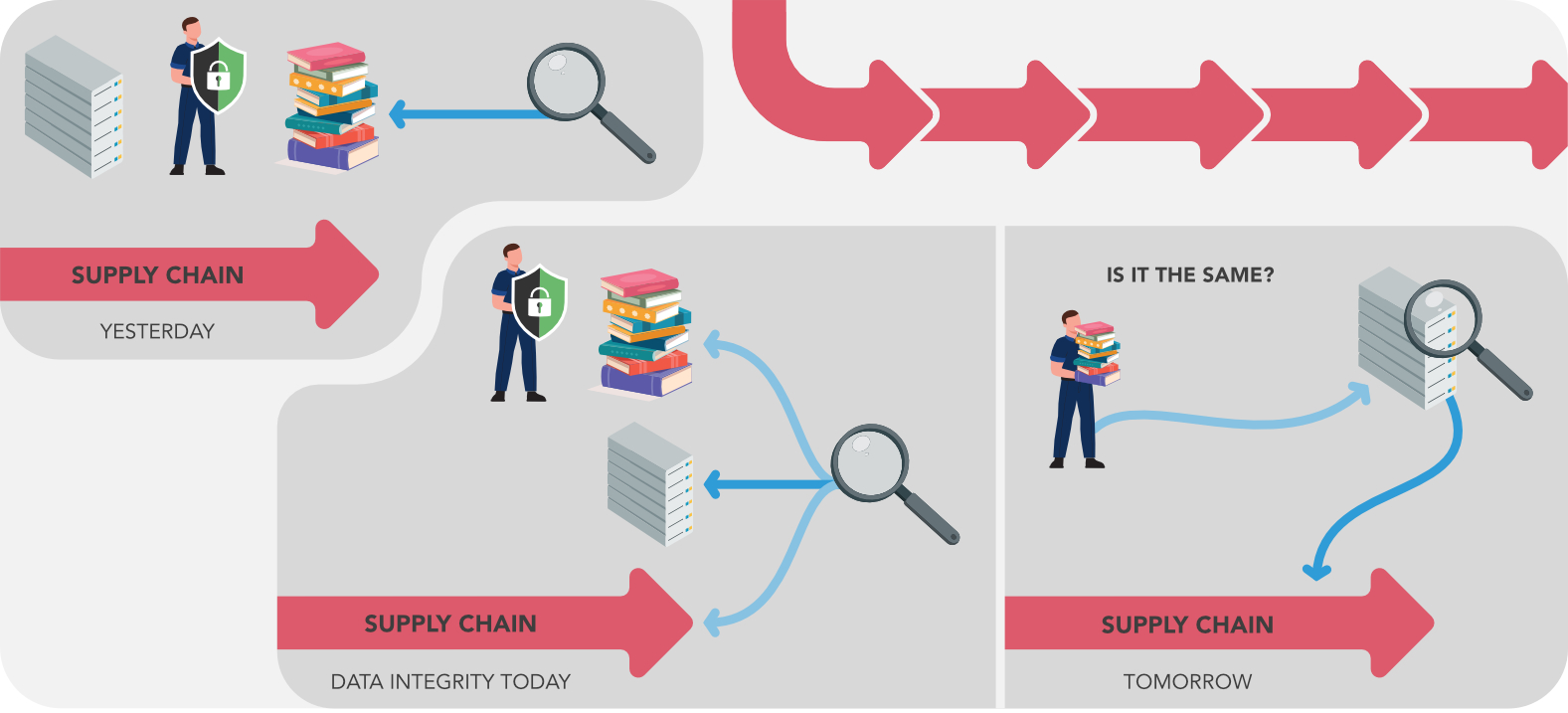
In the life science sector, data integrity is a very common concept that is often declined, and again, related only to the system functionalities (audit trail, etc.). In reality, this approach is a ‘necessary and not sufficient condition’ to have ‘real’ data integrity because the main threats are related to how the system is used. Nobody thought that having qualified the equipment would confirm the product is good, but in my experience a lot of people think that having validated a system (the IT equipment) according to part 11 automatically they have complete data integrity: this is one of the major problems in production, when equipment are qualified and afterwards, there is the batch record to manage product quality. In IT, generally the validation is related to each single system.
The topic: consider the production of data compared to the physical supply chain
It is common sense that information is a company asset and that competition will be based upon information.
Therefore, if it is true that a company produces both information and product, we should compare how differently they are managed.
|
Supply chain |
Information chain |
|
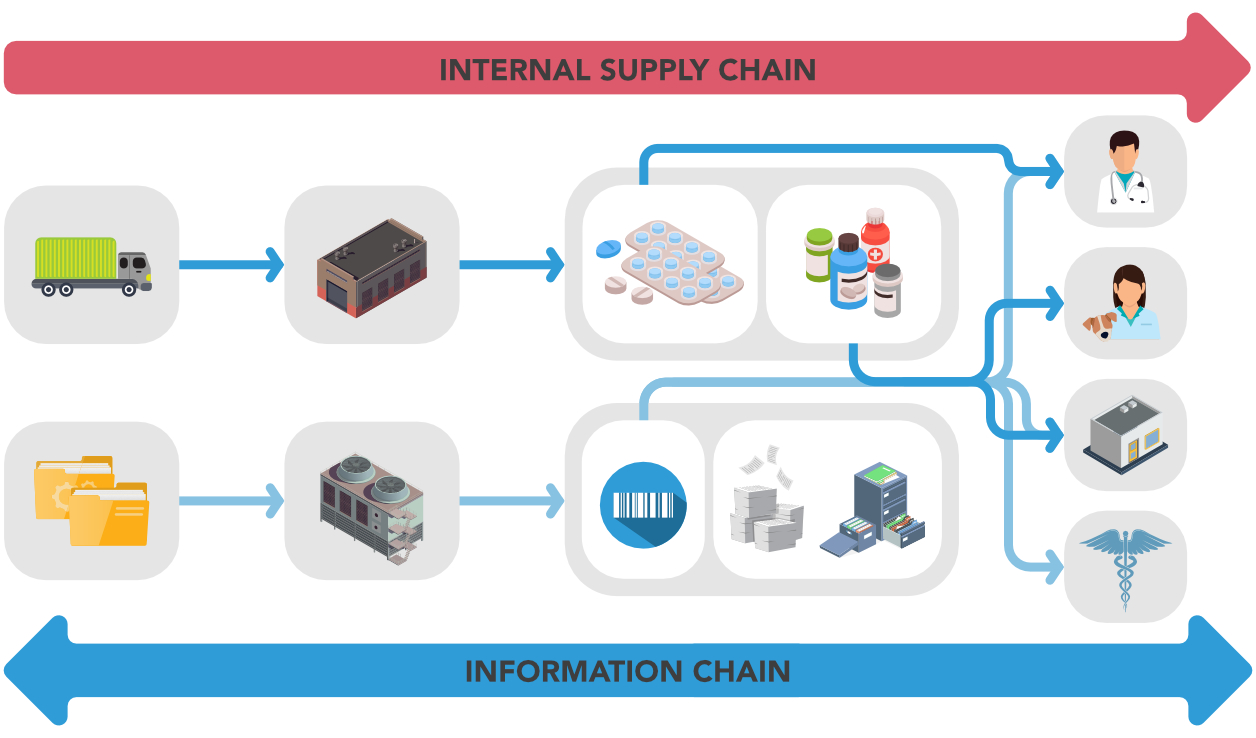
Company produces goods, transforming them from raw material to finished goods and distributes to customer. An effective supply chain is important for the company’s final results.
|
Company produces information (labels, packaging, but also reports, certificates, etc.) for the market or notified or regulatory bodies. The information managed has an increasing value and high impact on company results and reputation. |
|
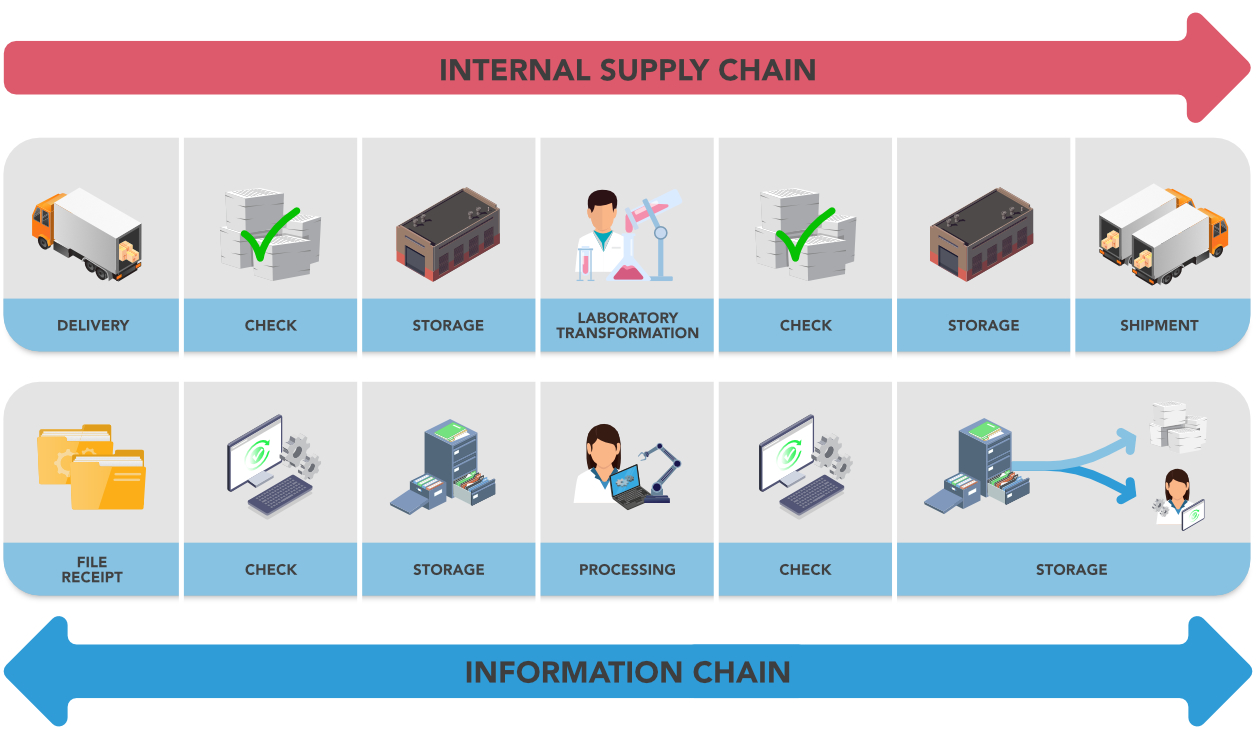
The physical management requires one or more sequences for receiving, controlling, stocking, transforming and sending goods.
|
The process is very similar: raw data is received, archived, transformed, etc., but there is a difference in managerial accountability: the warehouse is locked to preserve the goods (how is IT security managed? How are information values preserved?) In the warehouse there are incoming and continuous controls to preserve the information. |
|
The process and company is controlled by many controllers; they can be customers, notified bodies or regulatory bodies (FDA, AIFA, ANSM, etc.). The control is generally executed by inspections. To expose the quality of the process there is a documentation set (generally paper-based) that is shown.
|
The information chain is also controlled more and more (and by multiple figures: e.g. GDPR, Finance, etc.). The control of the information chain has these advantages:
The point of data integrity is due to the need to have data that completely match the process. For this reason, the documentation-set paper base can become a huge burden since it should be justified against the data in the system: we hope that the quality should no longer be evaluated on the weight of paper. |
|
Cost control: there are multiple methodologies to keep costs under control. |
What will happen if we try to calculate the costs for all information chains? Everyone in the company works at the information chain level (more than in the physical level), and should be calculating:
|
|
With respect to the managerial aspect, the difference is bigger: the supply chain is generally managed by a supply manager (sometimes a production manager is the deputy) that coordinates all phase of processes inside the company. |
Situations regarding information chains vary: in some small companies, IT doesn’t exist! In larger companies, instead of thinking of the information chain, products are referred to (ERP, MES, SCADA etc.), and often, there is a clear separation from IT and OT: the megatrends (data integrity, but also industry 4.0) require a holistic vision of the entire flow that manages information. |
Key takeaways
- A lot of information for the market must be produced
- Many (always more) look at the information that has been produced
- Information is the basis of one’s reputation
- Information (creation , management, etc.) carries a high cost
- Companies don't have anyone who does INFORMATION CHAIN MANAGEMENT internally; at most it has more or less extensive computer systems/equipment technicians (not always interconnected)
- The paper process is ineffective and expensive
AND with the huge increase of data and integration required by industry 4.0, the problem has become bigger.
It is clear that the problem is:
- MANAGERIAL - Who is the owner of the information CHAIN MANAGEMENT processes?
- What is the role of IT?
- ORGANIZATIONAL-MANAGEMENT - how flows are managed - how do I get the data just once and only in one place?
- TECHNICIAN – are IT tools adequate, how is the decision-making process, etc.?
So, according to the physical flow we NEED TO SPEAK ABOUT INFORMATION CHAIN MANAGEMENT and we have created many projects to integrate system functionalities, information flows reducing the effort in producing/managing information, and in the meantime, to increase the quality of data.
From these experiences we were able to create a knowledge base and a specific analysis methodology to speed up the assessment projects, overcoming the old concept of AS IS analysis versus TO BE analysis.



